在现实世界中容错就是真金白银。程序员并不完美,需求往往也不完善。正如航空工程师处理有缺陷的钢材和铝材一样,为了有效处理有缺陷的代码和数据,我们需要能够容错的系统,以防系统在遭遇突发状况时土崩瓦解。
和许多其他编程语言一样,Erlang也具备异常处理机制来捕获特定代码段的错误,不过它还有一套独一无二的可以有效处理进程故障的进程链接系统,我们即将在此进行讨论。
1.进程链接如何工作
Erlang进程意外退出时,会产生一个退出信号。所有与濒死进程链接的进程都会收到这个信号。默认情况下,接收方会一并退出并将信号传播给与它链接的其他进程,直到所有直接或间接链接在一起的进程统统退出为止(参见图1-2)。这种级联行为可以使一组进程像单个应用一样退出,因此系统整体重启时你不必担心是否还有残存下来未能完全关闭的进程。
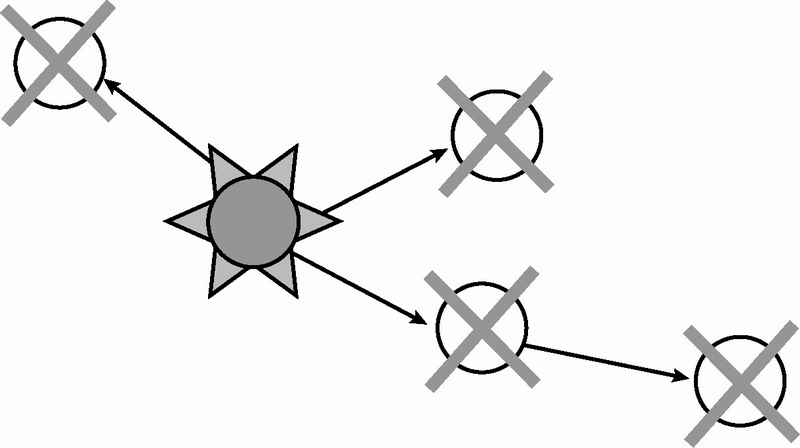
图1-2 崩溃进程发出的退出信号被传播到所有与之链接的进程,一般情况下它们会共同退出,以便完成对整个进程组的清理工作
前面我们曾提到过利用进程来清理复杂状态。其基本原理是:每个进程完整封装自己的全部状态,因此进程退出时系统的其余部分不会受损。如同单个进程一样,这一点对相互链接的进程组也同样适用。一个进程崩溃,与之协作的其他进程也一并退出,如此便可干净利落地抹掉之前建立的所有复杂状态,既节省了程序员的时间也减少了错误。
鼓励崩溃
当你还在绝望地纠结于如何挽回那些你可能根本无能为力的局面时,Erlang的哲学却是“鼓励崩溃”——精确记录下事发位置和经过后,把一切彻底抛下重新再来。这不太常见,但的确是一条强大的容错秘诀,而且按这个思路建立起来的系统无论多复杂度都可调试。
2.监督与退出信号捕捉
OTP实现容错的主要途径之一就是改写退出信号默认的传播行为。通过设置trap_exit进程标记,你可以令进程不再服从外来的退出信号,而是将之捕捉。这种情况下,进程接收到信号后,会先将其转为一条格式为{'EXIT', Pid, Reason}的消息,该消息描述了哪个进程出于什么原因而发生故障,然后这条消息会像普通消息一样被丢入信箱,捕捉到信号的进程就能分检并处理这类消息了。
这类会捕捉信号的进程有时被称为系统进程,它们执行的代码往往有别于普通的工作进程(即通常不捕捉信号的进程)。身为防范退出信号进一步传播的壁垒,系统进程阻断了与之链接的其他进程和外界之间的联系,因而可用于汇报故障乃至重启故障的子系统,正如图1-3所示。我们将这类进程称为监督者。
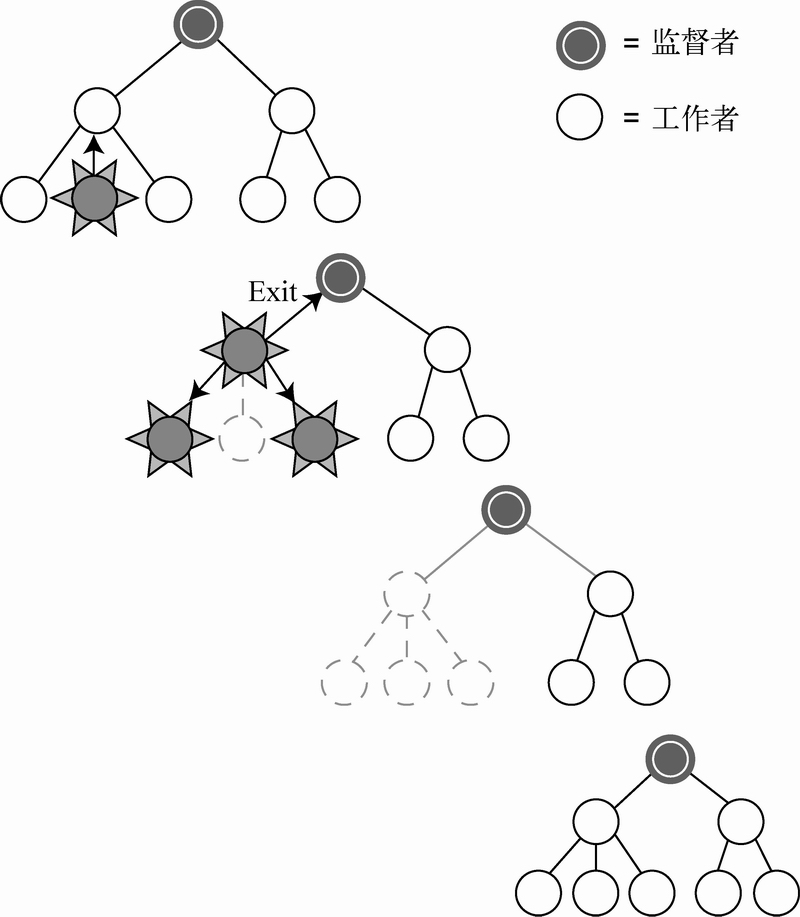
图1-3 监督者、工作者和信号:某工作进程的崩溃被级联传播至所有与之链接的其他进程,信号传播至监督者后,监督者将进程组重启。同一监督者辖区内的其他进程组则不受影响
停止并重启整个子系统的目的在于将系统恢复到一个已知的可正常工作的状态。这有点类似于重启电脑:通过重启你可以快刀斩乱麻地将电脑迅速恢复到可工作状态。但重启整台电脑的问题在于粒度太大。理想状况下,应该可以只重启系统的一部分,粒度越小越好。Erlang的进程链接与监督者共同提供了一种细粒度的“重启”机制。
不过,如果就到此为止,你还是得自己从头实现监督机制,这需要缜密的思考和丰富的经验,bug的清除和各种边界情况的处理也要花费大量的时间。幸运的是,OTP框架提供了你所需要的一切:既有运用监督机制来构建应用程序的一套方法,也有稳定的、经过实战考验的基础库。
OTP允许监督者按预设的方式和次序来启动进程。我们还可以告知监督者如何在单个进程故障时重启其他进程、一段时间内尝试重启多少次后放弃重启等。你所要做的就是提供一些参数和回调。
然而系统不应该只允许一层监督者工作者结构。在任何复杂系统中,你都可以用多层的监督树在多个层级重启子系统来解决各种意外问题。
3.进程的分层容错
通过分层可以将相关的子系统归于同一个监督者的辖区之内。更重要的是,这样做可以定义多个层级的基准工作状态,随时供你重置。在图1-4中,你可以看到两个分别受独立监督进程监督的工作进程组A和B。这两个组和它们的监督者共同形成了一个更大的进程组C,并由树中更高层的一个监督者负责。
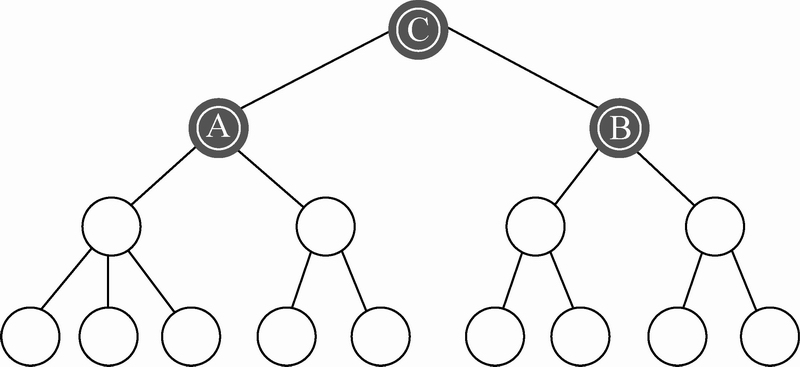
图1-4 一个分层的监督者工作者系统。如果出于某种原因监督者A崩溃或退出,它辖区内所有尚还存活的进程都会被强制关闭,同时C会收到通知,于是进程树的左半边会被重启。监督者B则不受影响,除非C决定关闭整个系统
我们假设A组进程的任务是输出供B组使用的数据流。无须B组,A组也可正常工作。更具体一点,比方说A组在处理和编码多媒体数据,B组则予以展现。我们再假设A组处理的数据中有一小部分受损,且数据损坏的模式无法在开发应用时预测。
这种畸形数据会导致A组的进程工作异常。按照鼓励崩溃的哲学,进程不会尝试去解决问题而是直接崩溃;由于进程相互隔离,其他进程并不会受到错误输入的影响。监督者检测到进程崩溃后,会将A组重启以回退到预设的基准状态,从而使整个系统恢复到一个已知的基准点。美妙的是身为展现系统的B组完全不知晓也不关心这个过程。只要A组能为B组持续提供足够的优质数据,使后者能为用户展现质量过关的内容,你的系统就是成功的。
通过隔离系统中不相关的部分并将它们组织成监督树,你可以划分出多个子系统,每个都可独立地在几分之一秒内完成重启,这样一来,即便你的系统碰上不可预期的错误也可以稳健地运行。若A组无法正常重启,它的监督者最终会放弃重启并将问题上报至C组的监督者。在这种情况下,C组的监督者会一并关闭B组然后停工。想象一下若系统中同时运行着几百个C这样的子系统,这就相当于因数据错误而丢弃了一个多媒体连接,其他连接仍然照常工作。
然而,既然大家都跑在同一台机器上,就不得不共用一些东西:内存、硬盘驱动器、网络连接,乃至处理器和所有相关电路,还有一样最重要的,就是从同一个插座上接出来的那根电源线。如果这些东西中有一样发生故障或断开,不管怎么分层怎么做进程隔离都无法避免宕机。这就把我们带入了下一个主题,也就是分布式——能助你实现最高级别的容错并令你的解决方案伸缩自如的,正是Erlang的这个特性。
本文摘自——《Erlang/OTP并发编程实战》
分享到:





相关推荐
java/c程序员开发erlang的资料
从Erlang.org的Programming rules翻译的中文版本
诊断以及调试生产环境中的Erlang 系统。在程序员学习新的语言和环境时,都需要一个摸索 阶段,也就是学会在社团的帮助下,脱离指南,解决实际问题。 本书假设读者精通基本的Erlang和OTP框架。在本书中,会对一些难以...
本软件是纸黄金、纸白银、纸铂金、纸钯金交易的得力助手; 主要功能有: 1、数据信息采用基于HTML5的大负载架构设计(Erlang)的长连接推送技术,高效且节省资源; 2、提供金融短讯、操作建议、经验秘籍等栏目功能;...
不同层次的Erlang程序员都会发现本书是有价值的学习和参考资料。”, ——Steve Vinoski,《IEEE Internet Computing》专栏作家, 《Erlang编程指南》是对Erlang语言的深入介绍。Erlang是任何必须并发、容错和快速响应...
5.2.分布和容错 5.3.表分片 5.4.本地内容表 5.5.无盘节点 5.6.更多的模式管理 5.7.Mnesia.事件处理 5.8.调试.Mnesia.应用 5.9.Mnesia.里的并发进程 5.10.原型 5.11.Mnesia.基于对象的编程 6.Mnesia....
Erlang并发编程,Erlang程序设计,Erlang中文手册。 学习erlang的好资料。 Erlang是一个结构化,动态类型编程语言,内建并行计算支持。最初是由爱立信专门为通信应用设计的,比如控制交换机或者变换协议等,因此...
erlang 中文基础教程erlang 中文基础教程
一款erlang 功能较全的webfrmework
第二部分讲解如何在实际开发中逐一添加otp 高级特性,从而完善应用,作者通过贯穿本书的主项目——加速web 访问的分布式缓存应用,深入浅出地阐明了实践中的各种技巧;第三部分讨论如何将代码与其他系统和用户集成,...
●外部接口-Erlang进程与外部世界之间的通讯使用和在Erlang进程之间相同的消息传送机制。 ●Fail-fast(中文译为速错),即尽可能快的暴露程序中的错误。 ●面向并发的编程(COP concurrency-oriented programming) ...
1、数据信息采用基于HTML5的大负载架构设计(Erlang)的长连接推送技术,高效且节省资源; 2、提供金融短讯、操作建议、经验秘籍等栏目功能; 3、应用运行时可设置是否待机功能,应用在后台运行时根据设置可关闭在线...
Match:在JavaScript中实现类似于Erlang的模式匹配
erlang入门电子书 erlang编程 Introducing Erlang,作者Simon.St.Laurent
erlang 安装包
erlang中文基础教程
ErlangB和ErlangC计算工具(exe可执行文件+excel两个) ErlangB和ErlangC计算工具(exe可执行文件+excel两个)
Erlang及其应用Erlang及其应用Erlang及其应用
erlang25.0 windows版本